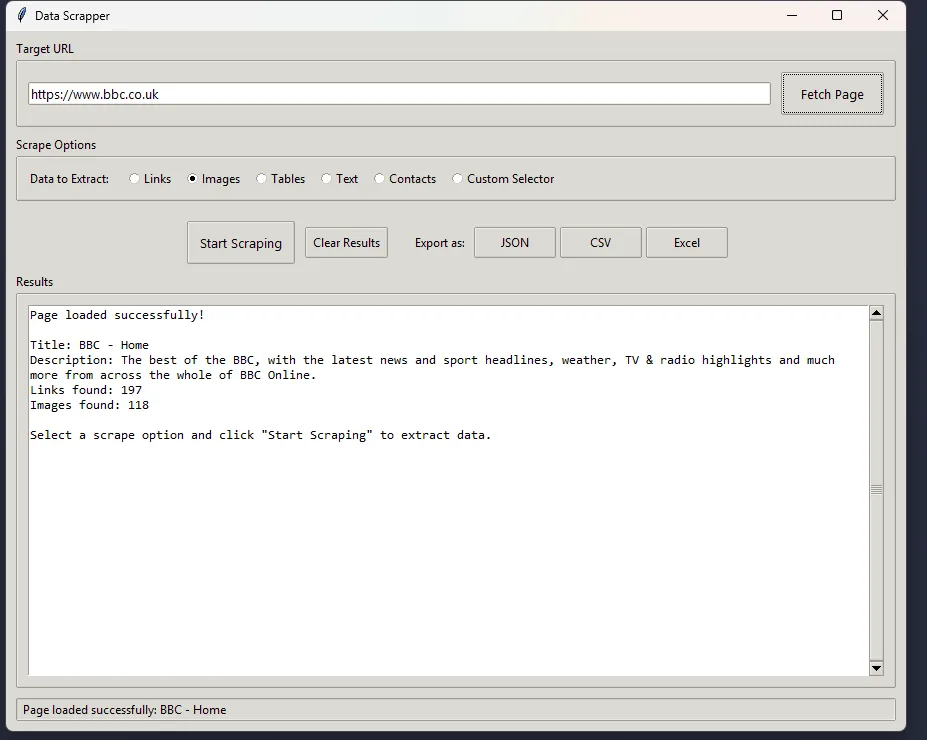
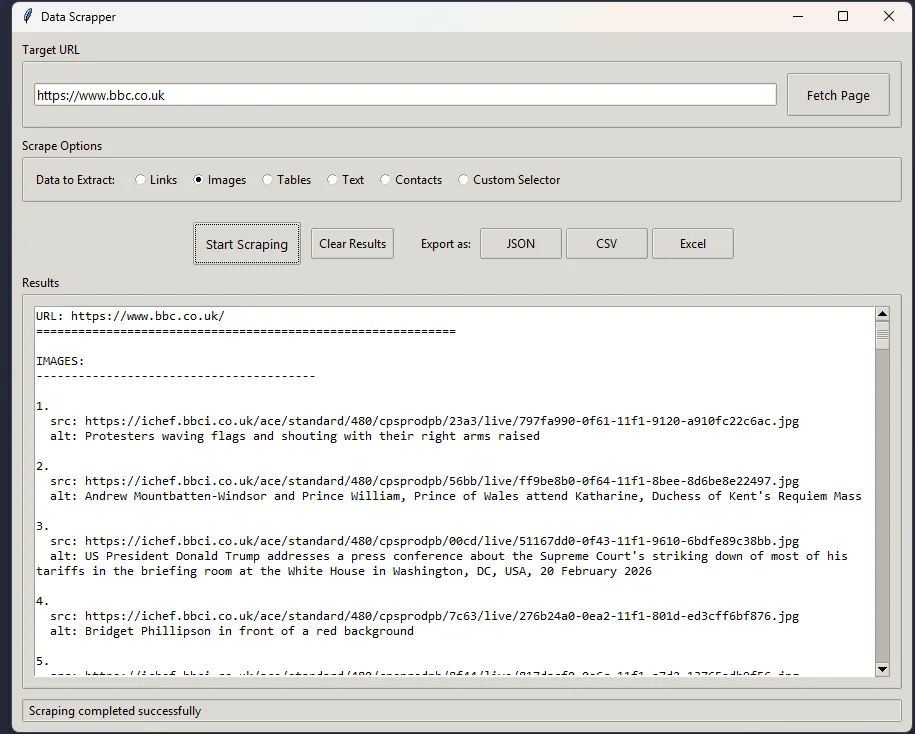
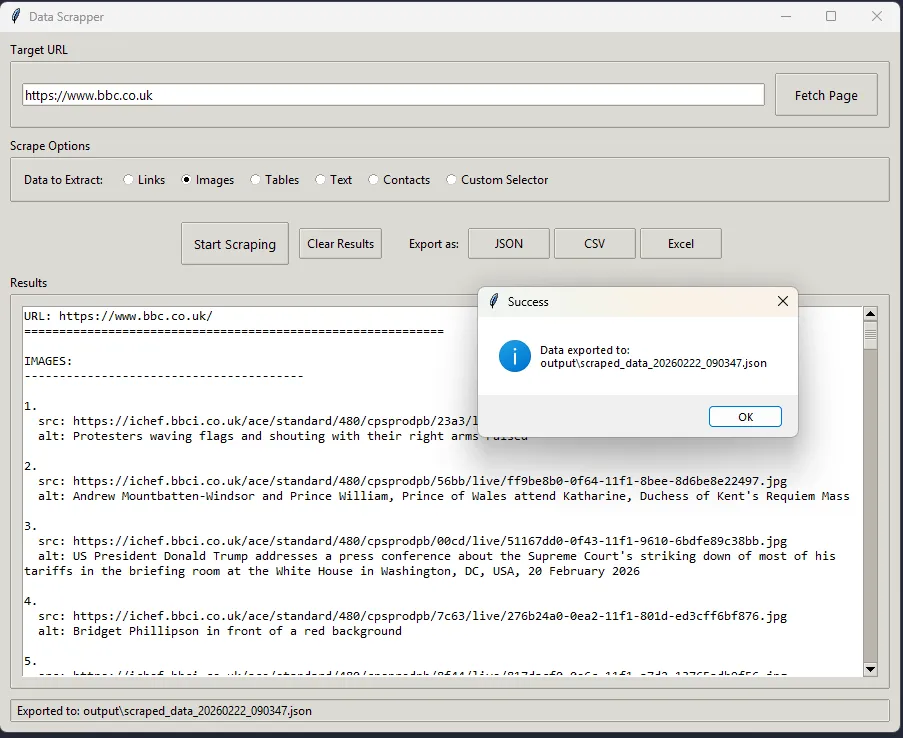
Data Scraper is a modular, easy-to-use web scraping application I developed using Python and TTkinter for the GUI. It provides a user-friendly interface for extracting data from websites with fully automated testing powered by Pytest.
The application is designed with modularity in mind, making it easy to extend and customise for different scraping needs. It features a clean architecture that separates concerns between the UI, scraping logic, and data export functionality.
The application uses pytest for automated testing, with both unit and integration tests covering the main features. The tests check the HTTP client, including URL validation, timeouts, and error handling. Network requests are mocked so no real internet calls are made. HTML parsing tests confirm that elements can be correctly extracted using selectors, tags, classes, and IDs. They also verify links, images, tables, and ensure the app handles malformed HTML without crashing. Data extraction tests confirm the system can accurately detect predefined text patterns and structured information within sample content. Export tests cover JSON, CSV, Excel, and text formats, including unicode support, custom headers, and timestamps. Integration tests ensure the main scraper works as a whole — combining scraping, caching, and exporting — using mocked responses for fast and reliable testing.
Current features include:
- Intuitive graphical user interface built with TTkinter
- URL fetching with configurable parameters
- Data extraction and parsing capabilities
- Export functionality to various formats
- Comprehensive test suite with Pytest
- Modular architecture for easy extensibility